 Photo: PEMAC.
Photo: PEMAC. 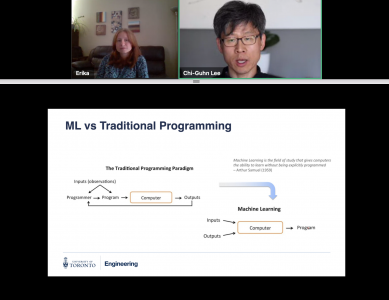
Photo: PEMAC.
PEMAC Asset Management Association of Canada GTA Chapter hosted a professional development event, with insights from a hands-on machine learning example utilizing a basic algorithm.
Presenter Chi-Guhn Lee, Professor of Industrial Engineering and the Director of the Centre for Maintenance Optimization and Reliability Engineering, University of Toronto, analyzed machine learning in this workshop and walked through the basic steps of machine learning using the simple linear programming model. He covered basic mathematical equations, including gradient descent.
The topic was about utilizing machine learning in a wide range of applications such as supply chain, finance, security and physical asset management.
“You don’t have to go too far to find AI,” said Lee. “if you pull out your smartphone, then you have AI in it, and in case you are using iPhone, you have Siri responding to your request. You can search the internet for specific keywords by talking to your phone and that’s AI algorithm.”
According to Lee, the professional world is not lacking AI applications either. For example, there is an AI lawyer known as Ross, among many, whose accuracy has been reported to be higher than a human lawyer. The reported accuracy of Ross is 90 per cent, as opposed to human only 70 per cent.
In healthcare, IBM Watson has been serving hospitals based on subscription service, and in some diagnostic tasks, AI doctors show higher accuracy than human doctors as much as four times.
In Wall Street, or Bay Street in Canada, there are AI-based investment advisors, and Numerai is an example of many. Also, Tesla cars and autonomous driving is an example of artificial intelligence.

Photo: PEMAC.
Lee explained the different between artificial intelligence (AI), Machine Learning (ML), and deep learning (DL). According to Lee, AI is any computer algorithm that mimics human behavior. ML is a particular technology in AI that gains ability by learning from data, so any AI algorithm that becomes smarter by learning from data can be seen as machine learning.
Deep learning is a particular technique within machine learning. In deep learning, a particular model is used for learning, and that model is deep neural network.
“So, we have this one directional relationship; AI is a superset, machine learning is within AI, and again deep learning is one particular branch of machine learning,” said Lee.
Lee discussed the three different categories of learning algorithms. The first category is
known as “supervised machine learning,” and this algorithm requires not only features, but also answers, so in some sense the machine learning algorithm needs a series of questions as well as answers to those questions and those answers are called “labor” using machine learning terminology.
The second category of learning algorithms is called “unsupervised machine learning,”; an option that is relied on whenever the answer part is missing.
“So, we have a bunch of questions but no answers, but still, by studying those questions, we can learn something, and such machine learning algorithm is called unsupervised motion learning algorithm,” said Lee.
The last branch of machine learning is “reinforcement learning,”, which is mainly for decision making. This is a different breed than the first two machine learning categories. Reinforced learning does not require any data; it requires a platform or an environment, so once reinforced learning algorithm is put in a situation then the learning algorithm will interact with the situation and collect data on its own.
Lee then explained the differences between machine learning and traditional computer programming. He also explained how the machine learning program paradigm works in detail:
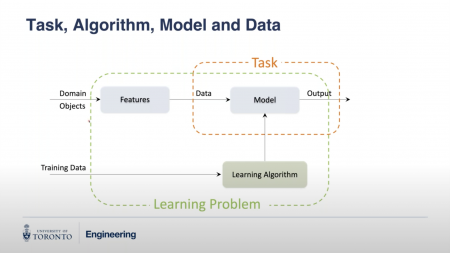
Figure 1. Photo: PEMAC.
“We have ‘domain’ like in the world that we are living in and we need objects, like myself. So, I am an object and we are interested in predicting the height of a person based on maybe gender, weight, etc. So, this object can be me, but what we are interested in is height, so that’s the ‘feature’, which can be the basis of data to the ‘model’, and once we train this model then it can predict the height of some object given features,” said Lee. “This is machine learning, and ‘task’ is defined by ‘model’, ‘data’ and ‘output’. This can be prediction of the height of the person or stock price tomorrow, or this task can be whether or not this machine will be up and running as of next week. So, we are trying to predict the health condition of our equipment.”
“This model will have to be trained so that we need learning algorithm here, so we have learning algorithm changing some of the parameters of this model so that this model can predict output more accurately, and to train this model what learning should be done we need training data. So, given data, learning algorithm makes changes to the model and then eventually, upon completion of training this model, can predict height, stock price, health condition of your equipment, accurately given features like vibration data and temperature and so on,” said Lee.
This process, including the definition of features, model and learning algorithm (the whole green box, figure 1) is machine learning.
Lee spoke about linear regression and gave examples of machine learning with linear model. He spoke about gradient descent for ML and gradient descent for linear regression.